kaggle の Digit Recognizer に挑戦する (3)
前回、kaggle の Digit Recognizer コンペティションで、畳み込みニューラルネットワークを利用しました。このコンペティションの Code で最も投票数を集めているのが Introduction to CNN Keras - 0.997 (top 6%) です。この中に、データを拡張して学習する方法が紹介されていますので、今回はこれを試していきたいと思います。
データ拡張
今回試すデータの拡張とは具体的に言うと、元々の手書き文字画像から、角度を少し変えてみたり、上下左右に少し動かしてみたり、大きさを少し変えてみたりした画像を生成して、それらの画像も学習に利用する、というものです。これで大幅に精度が上がったと書かれています。これらの画像の生成には、keras の ImageDataGenerator が利用できるので、それを使っていきます。
まずは、畳み込みニューラルネットワークやコンペティションのことは一旦忘れて、単純に ImageDataGenerator を使って画像を生成してみます。データの下準備は、前回までとほぼ同じです。
from keras.models import Sequential from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten from keras.utils import to_categorical from keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt import seaborn as sns import numpy as np
train = np.loadtxt('/root/practice/digit/csv/train.csv', skiprows=1, delimiter=',') x_test = np.loadtxt('/root/practice/digit/csv/test.csv', skiprows=1, delimiter=',') # print(train.shape) # print(x_test.shape) # 1列目と2〜785列目を分ける y_train, x_train = np.split(train, [1], 1) # print(x_train.shape) # print(y_train.shape) # 形状を枚数 × 28 × 28 × 1 に変形する x_train = x_train.reshape(42000, 28, 28, 1) x_test = x_test.reshape(28000, 28, 28, 1) # print(x_train.shape) # print(x_test.shape) # 1枚分を取り出し表示させてみる plt.imshow(x_train[3]) # ラベル確認 # print(y_train[3])
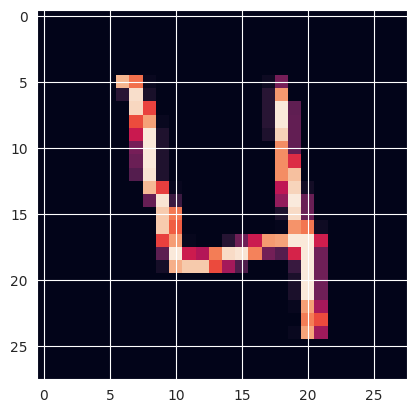
ここから ImageDataGenerator を使います。 今回はこの手書き数字「4」の画像を元画像として、これをコピーして3枚にし、これを使っていきます。
sample_images = np.array([x_train[3].copy(), x_train[3].copy(), x_train[3].copy()]) # -90 〜 90の範囲でランダムに回転 datagen = ImageDataGenerator(rotation_range=90) # 3枚の画像を生成するので batch_size = 3 戻り値はイテレータ g = datagen.flow(sample_images, batch_size=3) batches = g.next() #(枚数, 縦サイズ, 横サイズ, チャンネル数) --> (3, 28, 28, 1) になる # print(batches.shape) # 画像表示 plt.subplot(1, 3, 1) plt.imshow(batches[0]) plt.subplot(1, 3, 2) plt.imshow(batches[1]) plt.subplot(1, 3, 3) plt.imshow(batches[2])
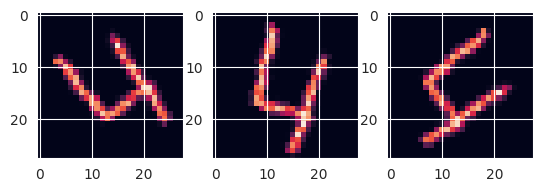
これで実際に画像を表示させてみると、「4」が回転している画像が3枚できたことがわかります。
学習
では、この ImageDataGenerator で、様々な画像データを生成して、学習していきます。CSVからデータを読み込み、訓練データと教師データを分ける処理などは上記と同じで、データの下準備と、ニューラルネットワークの構築部分は前回と同じです。
# 0 - 1 の間の数値にする x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # one-hot 表現にする y_train = to_categorical(y_train, 10) # モデルは前回の設定と同じ model = Sequential() model.add(Conv2D(filters=32, kernel_size=(4, 4), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(filters=64, kernel_size=(4, 4), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(64, activation='relu')) model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.summary()
それでは、ここから画像データを拡張していきます。
epochs = 30 batch_size = 86 datagen = ImageDataGenerator( rotation_range=10, # ランダムに10度回転する zoom_range=0.1, # ランダムに10%ズームする width_shift_range=0.1, # ランダムに横方向に10%ずらす height_shift_range=0.1 # ランダムに縦方向に10%ずらす ) # 第一引数は画像データ、第二引数はラベル generator = datagen.flow(x_train, y_train, batch_size=batch_size)
# 第一引数はデータを生成する generator、引数 steps_per_epoch は1エポック当たり generator を呼び出す回数 history = model.fit_generator( generator, epochs=epochs, steps_per_epoch=(x_train.shape[0] // batch_size), )
generator が生成するデータで学習をするときは、fit_generator メソッドを利用します。引数 steps_per_epoch は画像データ数をバッチサイズで割ったものを指定しています。これで1エポック当たりで、元々の画像データ数と同じ数のデータが生成されます。
学習が終わったら、誤差と精度を求めます。
loss, accuracy = model.evaluate(x_train, y_train) print(loss) print(accuracy)
前回(一つ前のブログ記事の (1) + (4) + (5) + (6))の結果と比較します。
| loss | accuracy | |
|---|---|---|
| 前回 | 0.008217111229896545 | 0.9972618818283081 |
| 今回 | 0.011472832411527634 | 0.9966190457344055 |
前回と比較して誤差・精度共に良い結果になりませんでした。
この学習後のニューラルネットワークで予測を行い、その結果を kaggle に提出してみます。
predicts = model.predict(x_test) # 最も値の大きいものが予測された値なので、それを取り出す predicts_label = np.argmax(predicts, axis=1) # CSVを出力するためのデータを生成 df = pd.DataFrame({ 'imageId': list(range(1, len(predicts)+ 1)), 'Label': predicts_label }) # CSV出力 df.to_csv("/root/practice/digit/csv/predictions.csv", index=False)
すると、なんとスコアが更新されました!!!!!!!!!

訓練データに対しては前回の結果を上回ることはできませんでしたが、テストデータに対しては良い結果を得ることができたようです。
kaggle の Digit Recognizer に挑戦する (2)
前回 kaggle の Digit Recognizer というコンペティションに挑戦しましたが、今回は、ニューラルネットワークの構成を変えて、畳み込みニューラルネットワークで学習をしたいと思います。畳み込みニューラルネットワークについては、私が理解するのに参考にした動画やサイトを、この記事の最後にリンクしておきましたので、そちらを参照してください。
データ
データの準備は前回とほぼ同じなので、記載を適宜割愛しますが、畳み込みニューラルネットワークへの入力を 28 * 28 * 1 にしないといけないので、その部分を調整していきます。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Conv2D, MaxPooling2D, Flatten from keras.utils import to_categorical import matplotlib.pyplot as plt import seaborn as sns import numpy as np import pandas as pd
# データ読み込み train = np.loadtxt('/root/practice/digit/csv/train.csv', skiprows=1, delimiter=',') x_test = np.loadtxt('/root/practice/digit/csv/test.csv', skiprows=1, delimiter=',') # print(train.shape) # print(x_test.shape) # 1列目と2〜785列目を分ける y_train, x_train = np.split(train, [1], 1) # print(x_train.shape) # print(y_train.shape) # 形状を 枚数 × 28 × 28 × 1 に変形する x_train = x_train.reshape(42000, 28, 28, 1) x_test = x_test.reshape(28000, 28, 28, 1) # print(x_train.shape) # print(x_test.shape) # 1枚分を取り出し表示させてみる # plt.imshow(x_train[0]) # ラベル確認 # print(y_train[0]) # 0 - 1 の間の数値にする x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # one-hot 表現にする y_train = to_categorical(y_train, 10) # print(y_train[0])
畳み込みニューラルネットワーク構築
それでは、畳み込みニューラルネットワークを構築していきます。
model = Sequential() # 畳み込み層 model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) # プーリング層 model.add(MaxPooling2D(pool_size=(2, 2))) # 出力を1次元にする model.add(Flatten()) # 出力層 model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
max_pooling2d (MaxPooling2D (None, 13, 13, 32) 0
)
flatten (Flatten) (None, 5408) 0
dense (Dense) (None, 10) 54090
=================================================================
Total params: 54,410
Trainable params: 54,410
Non-trainable params: 0
_________________________________________________________________
Conv2Dが畳み込み層になります。各引数の意味は下記の通りです。
- filters: 出力空間の次元=出力フィルタの数
- kernel_size: 2次元畳み込みウィンドウの大きさ
- activation: 活性化関数
- input_shape: 入力次元
MaxPooling2Dはプーリング層になります。引数 pool_size はプーリングするウィンドウの大きさです。
それでは学習していきます。
history = model.fit(x_train, y_train, epochs=5)
結果をグラフで表示します。
sns.lineplot(data=history.history["loss"])
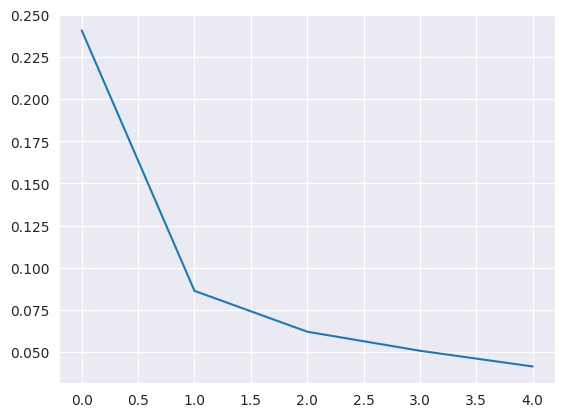
sns.lineplot(data=history.history["accuracy"])

学習が進むにつれて、誤差が減少し、精度が増加していくことがわかります。具体的な誤差と精度の数値も求めておきます(結果は後述)。
loss, accuracy = model.evaluate(x_train, y_train) print(loss) print(accuracy)
設定を変える
上で紹介した畳み込みニューラルネットワークの構成をベースとして、いろいろと一つずつパラメータや構成を変えて誤差と精度がどう変わるのか試してみます。変えたパラメータや構成以外はベースと同じです。今回は下記のようにパラメータ・構成を変えてみました。
(1) Conv2D の kernel_size を (4, 4) にする
(2) Conv2D の kernel_size を (2, 2) にする
(3) MaxPooling2D の pool_size を (3, 3) にする
(4) epochs を 10 にする
(5) 全結合層を追加する
(6) Conv2D, MaxPooling2D の層を追加する
「(5) 全結合層を追加する」は、具体的に下記のように設定しています。
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(64, activation='relu')) # この行を追加 model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.summary()
「(6) Conv2D, MaxPooling2D の層を追加する」は、具体的に下記のように設定しています。
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu')) # この行を追加 model.add(MaxPooling2D(pool_size=(2, 2))) # この行を追加 model.add(Flatten()) model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.summary()
それぞれの結果は下記の通りになりました。
| loss | accuracy | |
|---|---|---|
| ベース | 0.0354999378323555 | 0.9896904826164246 |
| (1) Conv2D の kernel_size を (4, 4) にする | 0.03126463294029236 | 0.9907143115997314 |
| (2) Conv2D の kernel_size を (2, 2) にする | 0.04609178006649017 | 0.9873571395874023 |
| (3) MaxPooling2D の pool_size を (3, 3) にする | 0.05607537552714348 | 0.9817143082618713 |
| (4) epochs を 10 にする | 0.015390428714454174 | 0.9960476160049438 |
| (5) 全結合層を追加する | 0.012460934929549694 | 0.9962618947029114 |
| (6) Conv2D, MaxPooling2D の層を追加する | 0.016651742160320282 | 0.9953095316886902 |
まず、畳み込み層の畳み込みウィンドウのサイズですが、学習する画像のサイズが28 × 28だと、3 × 3 よりも少し大きくした 4 × 4 の方が良いようです。学習回数は少なかったようで、epoch=10にしたら、良い結果が出ました。全結合層、Conv2D・MaxPooling2D の層を増やした方が良い結果が出ています。
この結果を踏まえて、ベースの設定から下記の設定を加えたもので再度学習し直してみます。
(1) Conv2D の kernel_size を (4, 4) にする
(4) epochs を 10 にする
(5) 全結合層を追加する
(6) Conv2D, MaxPooling2D の層を追加する
具体的には下記のような設定になります。
model = Sequential() model.add(Conv2D(filters=32, kernel_size=(4, 4), activation='relu', input_shape=(28, 28, 1))) # kernel_size を (4, 4) にする model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(filters=64, kernel_size=(4, 4), activation='relu')) # この行を追加 kernel_size を (4, 4) にする model.add(MaxPooling2D(pool_size=(2, 2))) # この行を追加 model.add(Flatten()) model.add(Dense(64, activation='relu')) # この行を追加 model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.summary() history = model.fit(x_train, y_train, epochs=10) # epochs を 10 にする
上記の設定の結果は下記のようになりました。今までで一番良い結果になりましたね。
| loss | accuracy | |
|---|---|---|
| (1) + (4) + (5) + (6) | 0.008217111229896545 | 0.9972618818283081 |
予測
それでは、上記構成で予測します。前回と同様のソースです。
predicts = model.predict(x_test) # 最も値の大きいものが予測された値なので、それを取り出す predicts_label = np.argmax(predicts, axis=1) # CSVを出力するためのデータを生成 df = pd.DataFrame({ 'imageId': list(range(1, len(predicts)+ 1)), 'Label': predicts_label }) # CSV出力 df.to_csv("/root/practice/digit/csv/predictions.csv", index=False)
CSVが出力されたので kaggle に提出します。

おおおおおおおおおおおお!前回よりもスコアとランキングが上がりました!!
参考にしたサイト
kaggle の Digit Recognizer に挑戦する(1)
今回は kaggle の Digit Recognizer というコンペティションに挑戦したいと思います。このコンペティションは簡単に言うと画像認識で、0〜9の数字を手で書いた画像があるので、それが何の数字なのかを予測する、というものです。なお、開発は Jupyter Notebook を利用し、環境は Docker tensorflow/tensorflow:latest-jupyter イメージで構築しています。
MNIST のデータ
実は MNIST にも同じようなデータがあり、こちらの方が理解しやすいので、まずはこちらを説明します。手書きの数字画像は縦28×横28ピクセルの画像で、各ピクセルには色の濃淡を表す0〜255までの整数が入っています。この数値は、0だと真っ白で、255だと真っ黒を表します。MNIST のデータは解説しているサイトがたくさんありますので、例えばこちらのサイトを参照してもらえば、何を言っているのかすぐに理解してもらえると思います。
では、実際にダウンロードして確かめてみます。
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout from keras.utils import to_categorical import matplotlib.pyplot as plt import seaborn as sns import numpy as np import pandas as pd
(xm_train, ym_train), (xm_test, ym_test) = mnist.load_data()
print(xm_train.shape)
(60000, 28, 28)
60000 × 28 × 28 の numpy.ndarray であることが確認できます。縦28×横28ピクセルの画像データが60000枚あるということです。matplotlib の imshow() を使うと、画像で表示することができます。
plt.imshow(xm_train[0])
対応するラベル y_train を確認します。
print(ym_train[0])
5
手書き数字画像と、ラベルが一致することが確認できました。
kaggle のデータ
kaggle のデータはMNISTのデータとはちょっと違います。実際にデータをダウンロードし、データを読み込んで中身を確認します。
train = np.loadtxt('/root/practice/digit/csv/train.csv', skiprows=1, delimiter=',') x_test = np.loadtxt('/root/practice/digit/csv/test.csv', skiprows=1, delimiter=',') print(train.shape) print(x_test.shape)
(42000, 785) (28000, 784)
訓練データは 42000 × 785 になっています。42000は手書き数字画像の枚数です。785は、1列目はラベル、即ち手書き画像の数値が何かを表したもので、2〜785列目は縦28×横28ピクセルの画像データを横一列に並べたものものです。28 × 28 = 784 なので数も合いますね。テストデータは、訓練データと比較して、ラベルの列が無いものになります。
実際にデータを加工して確かめてみます。
# 1列目と2〜785列目を分ける y_train, x_train = np.split(train, [1], 1) print(x_train.shape) print(y_train.shape)
(42000, 784) (42000, 1)
# 1枚分を取り出し 28 * 28 の形にして表示させてみる plt.imshow(x_train[0].reshape(28, 28))

# ラベル確認 print(y_train[0])
[1.]
画像が表示され、ラベルと一致することが確認できました。
データ準備
学習をする前にデータの下準備をしていきます。
# 0 - 1 の間の数値にする x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255
# one-hot 表現にする y_train = to_categorical(y_train, 10) print(y_train[0])
[0. 1. 0. 0. 0. 0. 0. 0. 0. 0.]
ラベルの方を one-hot 表現にしています。訓練データの最初の数値は1でしたから、(0から数えて)1を表すところが1になっていて、後は全て0になっていることが確認できます。
学習
それでは、ニューラルネットワークを構築して学習していきます。
# ニューラルネットワーク構築 model = Sequential() # [中間層] ユニット数:12, 活性化関数:relu, 入力次元数:784 model.add(Dense(units=12, activation='relu', input_dim=784)) # [出力層] ユニット数:10, 活性化関数:ソフトマックス model.add(Dense(10, activation='softmax')) # 損失関数:categorical_crossentropy, 最適化アルゴリズム:rmsprop model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy']) model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 12) 9420
dense_1 (Dense) (None, 10) 130
=================================================================
Total params: 9,550
Trainable params: 9,550
Non-trainable params: 0
_________________________________________________________________
各層の設定はソース内のコメントとして書きましたので、参照してください。
それでは学習していきます。
# バッチサイズ:128, 反復数:20 history = model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=1)
結果をグラフで表示します。
sns.lineplot(data=history.history["loss"])

sns.lineplot(data=history.history["accuracy"])

学習が進むにつれ、誤差が減少し、精度が増加していくことがわかります。
設定を変える
最適化アルゴリズムを adam に変えて試してみます。具体的には下記の optimizer 引数を adam に変更します。他の設定は全く同じです。
# 損失関数:categorical_crossentropy, 最適化アルゴリズム:adam model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])


誤差、精度ともに少し改善したようです。
中間層のユニット数を128に増やしてみます。最適化アルゴリズムは adam を利用し、その他設定は同じです。具体的な修正箇所は下記です。
# [中間層] ユニット数:128, 活性化関数:relu, 入力次元数:784 model.add(Dense(units=128, activation='relu', input_dim=784))


誤差、精度ともに大幅に改善されたようです。 evaluate メソッドで具体的な数値も比較してみます。
loss, accuracy = model.evaluate(x_train, y_train, verbose=1)
| loss | accuracy | |
|---|---|---|
| rmsprop | 0.1851324439048767 | 0.9472380876541138 |
| adam | 0.1607203185558319 | 0.9545952677726746 |
| adam + Unit数128 | 0.00736998999491334 | 0.9989285469055176 |
数値を見ても改善されているのが確認できます。
予測
では、 adam + 中間層ユニット数128 の設定で、テストデータを予測したいと思います。
predicts = model.predict(x_test) # 0 - 9 の10列のうち、最も値の大きいものが予測された値なので、それを取り出す predicts_label = np.argmax(predicts, axis=1)
# CSVを出力するためのデータを生成 df = pd.DataFrame({ 'imageId': list(range(1, len(predicts)+ 1)), 'Label': predicts_label }) print(df.tail())
| imageId | Label | |
|---|---|---|
| 27995 | 27996 | 9 |
| 27996 | 27997 | 7 |
| 27997 | 27998 | 3 |
| 27998 | 27999 | 9 |
| 27999 | 28000 | 2 |
# CSV出力 df.to_csv("/root/practice/digit/csv/predictions.csv", index=False)
無事にCSVが出力されたので、kaggle に提出します。

おおおおおおおおおおお!これも下から数えた方が早いですが、自分の名前が Leaderboard に刻まれました!!
参考にしたサイト
Kaggle のタイタニック問題をやってみる(2)
前回はタイタニック問題のデータの中身を調査しましたので、今回はそのデータを元に学習し予測していきたいと思います。
訓練データ準備
今回使いたいデータの項目は、Pclass(チケットクラス)と年齢と性別です。まずは、年齢について何とかします。欠損値がたくさんあったので、これを何とかしないといけません。欠損値を何か適当なそれっぽいデータで埋めようと思うので、Pclass(チケットクラス)毎に年齢の平均を出してみます。
import numpy as np import pandas as pd import seaborn as sns from sklearn.model_selection import train_test_split from keras.layers import Dense from keras.models import Sequential %matplotlib inline
df = pd.read_csv("/root/practice/titanic/csv/train.csv") df[["Pclass", "Age"]].dropna().groupby(["Pclass"]).mean()
| Pclass | Age |
|---|---|
| 1 | 38.233441 |
| 2 | 29.877630 |
| 3 | 25.140620 |
得られたPclass(チケットクラス)毎の年齢の平均値で、欠損値を埋めます。
# Age 欠損値を埋める def fill_age(value): if not np.isnan(value[1]): return value[1] pclass_age_map = { 1: 38, 2: 30, 3: 25 } return pclass_age_map.get(value[0], 0) df["Age"] = df[["Pclass", "Age"]].apply(fill_age, axis=1)
続いて、性別を0,1の値にして、学習に適した形にします。
# 性別を0, 1にする sex = pd.get_dummies(df["Sex"], drop_first=True, dtype=int) # 性別を0,1にしたデータを結合しておく --> male という列が最後にできている形になる df = pd.concat([df, sex], axis=1)
この時点でこのようなデータになっています。
df.head()
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S | 1 |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C | 0 |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S | 0 |
| 3 | 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35.0 | 1 | 0 | 113803 | 53.1000 | C123 | S | 0 |
| 4 | 5 | 0 | 3 | Allen, Mr. William Henry | male | 35.0 | 0 | 0 | 373450 | 8.0500 | NaN | S | 1 |
今回は、学習に利用する項目としてPclass(チケットクラス)と性別と年齢のみを対象にしたいので、必要な列を除いて(性別の元データ列も含めて)削除します。
# 不要カラム削除 df.drop(["Name", "Sex", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1, inplace=True)
そうすると、これだけスッキリしたデータになりました。
df.head()
| PassengerId | Survived | Pclass | Age | male | |
|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | 22.0 | 1 |
| 1 | 2 | 1 | 1 | 38.0 | 0 |
| 2 | 3 | 1 | 3 | 26.0 | 0 |
| 3 | 4 | 1 | 1 | 35.0 | 0 |
| 4 | 5 | 0 | 3 | 35.0 | 1 |
このデータで訓練データを作成します。作成には sklearn の train_test_splitを利用します。
X_train, X_test, y_train, y_test = train_test_split(
df.drop(["Survived"], axis=1),
df["Survived"],
test_size=0.10,
random_state=101
)
訓練データの元となるデータは、データから Survived 列を除いたもの(train_test_splitの第一引数)、教師データの元となるデータは Survived 列のデータ(train_test_splitの第二引数)になります。これで訓練データが作成できました。X_train, y_train の中身を確認しておきます。
X_train.head()
| PassengerId | Pclass | Age | male | |
|---|---|---|---|---|
| 825 | 826 | 3 | 25.0 | 1 |
| 8 | 9 | 3 | 27.0 | 0 |
| 689 | 690 | 1 | 15.0 | 0 |
| 513 | 514 | 1 | 54.0 | 0 |
| 729 | 730 | 3 | 25.0 | 0 |
y_train.head()
| Survived | |
|---|---|
| 825 | 0 |
| 8 | 1 |
| 689 | 1 |
| 513 | 1 |
| 729 | 0 |
学習
データの下準備はできたので、学習していきます。まずはニューラルネットワークを構築します。
model = Sequential() # [中間層] ユニット数: 32, 重み初期化方法: uniform, 活性化関数: reru, 入力: 4項目 model.add(Dense(units=32, kernel_initializer='uniform', activation='relu', input_dim=4)) model.add(Dense(units=32, kernel_initializer='uniform', activation='relu')) # [出力層] ユニット(出力)数: 1, 重み初期化方法: uniform, 活性化関数: シグモイド model.add(Dense(units=1, kernel_initializer='uniform', activation='sigmoid')) # 最適化アルゴリズム: adam, 目的(損失)関数: 平均二乗誤差 model.compile(optimizer='adam', loss='mean_squared_error', metrics=['accuracy'])
三層のニューラルネットワークを構築しました。各層の詳細な設定はソース内のコメントを参照してください。
それでは学習していきます。
# バッチサイズ: 32, 反復数: 300 history = model.fit(X_train, y_train, batch_size=32, epochs=300, verbose=1)
学習結果を折れ線グラフで表示させてみます。
sns.lineplot(data=history.history["loss"])

sns.lineplot(data=history.history["accuracy"])

学習を重ねる毎に誤差が減少し、精度が増加していくことがわかります。
テストデータ準備
学習ができたので、テストデータの予測していきます。 前回のブログでも書いた通り、訓練データから「生存フラグ」項目が無いものがテストデータになります。 データの準備は訓練データと同じなので、同じ手順でデータを加工していきます。
df_test = pd.read_csv("/root/practice/titanic/csv/test.csv")
df_test.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 418 entries, 0 to 417 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 418 non-null int64 1 Pclass 418 non-null int64 2 Name 418 non-null object 3 Sex 418 non-null object 4 Age 332 non-null float64 5 SibSp 418 non-null int64 6 Parch 418 non-null int64 7 Ticket 418 non-null object 8 Fare 417 non-null float64 9 Cabin 91 non-null object 10 Embarked 418 non-null object dtypes: float64(2), int64(4), object(5) memory usage: 36.0+ KB
df_test.isnull().sum().sort_values(ascending=False)
| data | |
|---|---|
| Cabin | 327 |
| Age | 86 |
| Fare | 1 |
| PassengerId | 0 |
| Pclass | 0 |
| Name | 0 |
| Sex | 0 |
| SibSp | 0 |
| Parch | 0 |
| Ticket | 0 |
| Embarked | 0 |
データ数は418行、テストデータの年齢の項目にも欠損値が多数あるようです。
# Age の欠損値を埋める df_test["Age"] = df_test[["Pclass", "Age"]].apply(fill_age, axis=1) # 性別を 0, 1 にする sex = pd.get_dummies(df_test["Sex"], drop_first=True, dtype=int) df_test = pd.concat([df_test, sex], axis=1)
df_test.head()
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | male | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 892 | 3 | "Kelly, Mr. James" | male | 34.5 | 0 | 0 | 330911 | 7.8292 | NaN | Q | 1 |
| 1 | 893 | 3 | "Wilkes, Mrs. James (Ellen Needs)" | female | 47.0 | 1 | 0 | 363272 | 7.0000 | NaN | S | 0 |
| 2 | 894 | 2 | "Myles, Mr. Thomas Francis" | male | 62.0 | 0 | 0 | 240276 | 9.6875 | NaN | Q | 1 |
| 3 | 895 | 3 | "Wirz, Mr. Albert" | male | 27.0 | 0 | 0 | 315154 | 8.6625 | NaN | S | 1 |
| 4 | 896 | 3 | "Hirvonen, Mrs. Alexander (Helga E Lindqvist)" | female | 22.0 | 1 | 1 | 3101298 | 12.2875 | NaN | S | 0 |
# 不要カラム削除 df_test.drop(["Name", "Sex", "SibSp", "Parch", "Ticket", "Fare", "Cabin", "Embarked"], axis=1, inplace=True)
df_test.head()
| PassengerId | Pclass | Age | male | |
|---|---|---|---|---|
| 0 | 892 | 3 | 34.5 | 1 |
| 1 | 893 | 3 | 47.0 | 0 |
| 2 | 894 | 2 | 62.0 | 1 |
| 3 | 895 | 3 | 27.0 | 1 |
| 4 | 896 | 3 | 22.0 | 0 |
予測
テストデータの準備ができたので、いよいよ予測していきたいと思います。
# 学習済みのニューラルネットワークで予測 test_predicts = model.predict(df_test) test_predicts = [ 1 if y >= 0.5 else 0 for y in test_predicts]
出力された値(予測)を0,1にするところまでできたので、予め決められた提出するファイルのフォーマットにする準備をします。
# 提出用のCSVを出力する準備 df_test_result = pd.DataFrame({ 'PassengerId': df_test['PassengerId'], 'Survived': test_predicts }) df_test_result.head()
| PassengerId | Survived | |
|---|---|---|
| 0 | 892 | 0 |
| 1 | 893 | 1 |
| 2 | 894 | 0 |
| 3 | 895 | 0 |
| 4 | 896 | 1 |
後はCSVに出力するだけです。
df_test_result.to_csv("/root/practice/titanic/csv/predictions.csv", index=False)
提出
予測結果をCSVに出力することができたので、提出してみます。 Titanic - Machine Learning from Disasterのページに行き、「Submit Predictions」ボタンを押下して、CSVファイルをアップロードします。 エラーが無ければ、アップロードに成功した旨の通知が来るので、Leaderboardで自分の順位を確認します。

おおおおおおお!圧倒的に下から数えた方が早い順位ですが、Leaderboardに自分の名前が刻まれました!
Kaggle のタイタニック問題をやってみる(1)
今までGoの記事を書いてきましたが、一旦お休みして、今回は kaggle の Titanic - Machine Learning from Disaster に挑戦しようと思います。挑戦とはいえ、初心者ですので、下記を Code を参考にしながら進めていきたいと思います。
まずは、データの中身を見ていきます。
データ
このタイタニック問題のデータの中身については、いろいろなサイトで解説されていますので、横着しますが、詳細はこちらのサイトを参照してもらえればと思います。データの項目として、乗客の名前やチケットクラス、年齢、性別などのデータと生存フラグがあります。訓練データにはこれら全ての項目があり、テストデータはこれらの項目の中から生存フラグが無いデータになります。
生存に大きく関与した項目として考えられるのは「年齢」「性別」「チケットクラス」が挙げられると思います。今回はシンプルに考えるためにも、この3項目に注目して、データの中身を見ていきたいと思います。その前にまずは、データ全体の概要を見ていきます。
データ概要
import numpy as np import pandas as pd import seaborn as sns %matplotlib inline df = pd.read_csv("/root/practice/titanic/csv/train.csv") df.info() df.isnull().sum().sort_values(ascending=False)
<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB
Cabin 687 Age 177 Embarked 2 PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 SibSp 0 Parch 0 Ticket 0 Fare 0 dtype: int64
データ数は891行、Cabin(客室番号)とAge(年齢)、Embarked(出港地)に欠損値があるようです。
チケットクラス
Pclass(チケットクラス)についてグラフにしてみます。
sns.set_style("whitegrid") sns.countplot(x="Pclass", data=df, hue="Survived")

Pclassの数値の意味ですが下記の通りで、上のクラスの人ほど生存率が高いことがわかります。
- 1:上層クラス
- 2:中級クラス
- 3:下層クラス
性別
性別についてグラフにします。
sns.set_style("whitegrid") sns.countplot(x="Sex", data=df, hue="Survived")

女性の方が生存率が高いことがわかります。
年齢
年齢についてグラフにします。
age_survived = df.query("Survived == 1 and Age > 0") age_not_survived = df.query("Survived == 0 and Age > 0") sns.histplot(x="Age", data=age_survived, bins=30, kde=True, color="green", alpha=0.5) sns.histplot(x="Age", data=age_not_survived, bins=30, kde=True, color="red", alpha=0.5)

10代以下の人の生存率が高いことがわかります。30代の生存者数は多いようですが、死亡者数も多いので生存率としては高くないようです。
その他要素
その他の要素についてもグラフにします。
兄弟/配偶者の数
sns.set_style("whitegrid") sns.countplot(x="SibSp", data=df, hue="Survived")

親/子供の数
sns.set_style("whitegrid") sns.countplot(x="Parch", data=df, hue="Survived")

料金
fare_survived = df.query("Survived == 1") fare_not_survived = df.query("Survived == 0") sns.histplot(x="Fare", data=age_survived, bins=30, kde=True, color="green", alpha=0.7) sns.histplot(x="Fare", data=age_not_survived, bins=30, kde=True, color="red", alpha=0.5)

出港地
sns.set_style("whitegrid") sns.countplot(x="Embarked", data=df, hue="Survived")

タイタニックに同乗している兄弟・配偶者の数、親・子供の数が0人以外だと、生存率が高いように見える、など気になるデータもありますが、今回はシンプルに考えたいので扱いません。
今回はデータの中身を調査して、下記のことがわかりました。
- 上層クラスの生存率が高い
- 女性の方が生存率が高い
- 10代の生存率が高い
次回はこれらの項目を元に学習していきたいと思います。
Go の Gin と GORM で API を作る(2)
前回は repository を修正したので、今回はそれを利用して handler を修正していきたいと思います。handler/api/article.go というファイルを新規に作成し、下記のように記述しました。
package handler_api import ( "bbs/repository" "errors" "github.com/gin-gonic/gin" "net/http" "strconv" ) // 1ページあたりいくつの記事を表示するか const perPage = 20 // ArticleRequest 記事投稿リクエストを受ける struct // バリデーションルールを binding に記述する // 最大文字数のバリデーション max を追加 type ArticleRequest struct { Name string `json:"name" binding:"max=255"` Body string `json:"body" binding:"required,max=10000"` } // GetArticles 掲示板の記事を取得する func GetArticles(c *gin.Context) { // クエリパラメータ取得 paramLimit := c.Query("limit") paramOffset := c.Query("offset") limit, _ := strconv.Atoi(paramLimit) offset, _ := strconv.Atoi(paramOffset) if limit == 0 { limit = perPage } articles, _, err := repository.GetArticles(limit, offset) if err != nil { // このエラーハンドリングは次回以降に説明 c.Error(err).SetType(gin.ErrorTypePublic) return } // レスポンスは json で返したいので下記のメソッドを利用する // レスポンスは repository.Article struct のスライス c.JSON(http.StatusOK, articles) } // CreateArticle 掲示板の記事を作成する func CreateArticle(c *gin.Context) { // バリデーション&バインド var req ArticleRequest if err := c.ShouldBindJSON(&req); err != nil { c.Error(err).SetType(gin.ErrorTypePublic) return } // DBに保存 article, _, err := repository.CreateArticle(req.Name, req.Body) if err != nil { c.Error(err).SetType(gin.ErrorTypePublic) return } // レスポンスは repository.Article struct c.JSON(http.StatusCreated, article) } // UpdateArticle 掲示板の記事を更新する func UpdateArticle(c *gin.Context) { // PathInfo のパラメータを取得 // ルーティングは下記のように設定する想定 // r.PUT("/article/:articleId", handler_api.UpdateArticle) paramArticleId := c.Param("articleId") articleId, _ := strconv.Atoi(paramArticleId) if articleId == 0 { err := errors.New("invalid ArticleId") c.Error(err).SetType(gin.ErrorTypePublic) return } // バリデーション&バインド var req ArticleRequest if err := c.ShouldBindJSON(&req); err != nil { c.Error(err).SetType(gin.ErrorTypePublic) return } // DBに保存 article, _, err := repository.UpdateArticle(articleId, req.Name, req.Body) if err != nil { c.Error(err).SetType(gin.ErrorTypePublic) return } c.JSON(http.StatusOK, article) } // DeleteArticle 掲示板の記事を更新する func DeleteArticle(c *gin.Context) { // PathInfo のパラメータを取得 paramArticleId := c.Param("articleId") articleId, _ := strconv.Atoi(paramArticleId) if articleId == 0 { err := errors.New("invalid ArticleId") c.Error(err).SetType(gin.ErrorTypePublic) return } // DBから削除 _, err := repository.DeleteArticle(articleId) if err != nil { c.Error(err).SetType(gin.ErrorTypePublic) return } c.JSON(http.StatusOK, nil) }
説明が必要そうな箇所には、ソース内にコメントを付けました。これで、正常系は問題無く動作することが確認できています。が、異常系で動かしてみると、いろいろと問題がありそうです。具体的には下記のような問題があります。
- クエリパラメータやPathInfoのパラメータが不正なパラメータのとき、期待通りの挙動にならない
- 更新・削除をするとき、対象となるレコードが存在しなくても、エラーにならない
- 更新するとき、キーの無い項目については更新しない、という仕様の方が良い?
次回は上記の問題点を解消していきます。
参考リンク
Go の Gin と GORM で API を作る(1)
Qiita に書いた記事「Go の Gin と GORM で最低限の掲示板を作るチュートリアル」で作った掲示板を改修していきたいと思います。今回は articles テーブルにCRUDするAPIを作っていきたいと思います。この記事では、DB articles テーブルに対するCRUD処理を書く repository/article.go 修正をします。
package repository import ( "gorm.io/gorm" "time" ) // Article 記事用の struct // gorm.Model 構造体を使えば ID, CreatedAt, UpdatedAt, DeletedAt の記述は省略できる // nullable なカラムについてはポインタ型を指定 type Article struct { ID int Name *string Body string CreatedAt *time.Time UpdatedAt *time.Time DeletedAt gorm.DeletedAt // 論理削除できるよう型を gorm.DeletedAt に変更 //gorm.Model } // GetArticles DBから記事を取得する func GetArticles(limit int, offset int) ([]Article, *gorm.DB, error) { // gorm.DB を取得 db, err := CreateDB() if err != nil { return nil, nil, err } var articles []Article // 実行 // 最新の投稿から表示したいので id の降順で並べ替えておく // limit, offset を追加してページネーションに対応 result := db.Limit(limit).Offset(offset).Order("id desc").Find(&articles) if result.Error != nil { return nil, nil, result.Error } return articles, result, nil } // CreateArticle DBに記事を保存する func CreateArticle(name string, body string) (*Article, *gorm.DB, error) { // 将来的に Article の中身(カラム)が増えてくれば、引数は中身をひとまとめにした struct が良さそう // gorm.DB を取得 db, err := CreateDB() if err != nil { return nil, nil, err } // DBへ投入するデータを作成 エスケープしたものを入れる name = template.HTMLEscapeString(name) body = template.HTMLEscapeString(body) article := Article{ Name: &name, Body: body, } // 実行 result := db.Create(&article) if result.Error != nil { return nil, nil, result.Error } return &article, result, nil } // UpdateArticle 記事を更新する func UpdateArticle(id int, name string, body string) (*Article, *gorm.DB, error) { // gorm.DB を取得 db, err := CreateDB() if err != nil { return nil, nil, err } // 更新するデータを作成 エスケープしたものを使う name = template.HTMLEscapeString(name) body = template.HTMLEscapeString(body) article := Article{ ID: id, Name: &name, Body: body, } // 実行 result := db.Save(&article) if result.Error != nil { return nil, nil, result.Error } return &article, result, nil } // DeleteArticle 記事を削除する func DeleteArticle(id int) (*gorm.DB, error) { // gorm.DB を取得 db, err := CreateDB() if err != nil { return nil, err } // 実行 article := Article{ID: id} result := db.Delete(&article) if result.Error != nil { return nil, result.Error } return result, nil }
UpdateArticle() DeleteArticle() 関数を追加しました。GOAMの書き方そのままですね。削除は論理削除です。次回は handler 側を編集して repository/article.go に作った関数を使いAPIを作成していきます。
【2023/06/18 追記】
エラーハンドリングを修正、Name と Body の内容はエスケープしてから保存するように修正しました。