kaggle の Digit Recognizer に挑戦する (3)
前回、kaggle の Digit Recognizer コンペティションで、畳み込みニューラルネットワークを利用しました。このコンペティションの Code で最も投票数を集めているのが Introduction to CNN Keras - 0.997 (top 6%) です。この中に、データを拡張して学習する方法が紹介されていますので、今回はこれを試していきたいと思います。
データ拡張
今回試すデータの拡張とは具体的に言うと、元々の手書き文字画像から、角度を少し変えてみたり、上下左右に少し動かしてみたり、大きさを少し変えてみたりした画像を生成して、それらの画像も学習に利用する、というものです。これで大幅に精度が上がったと書かれています。これらの画像の生成には、keras の ImageDataGenerator が利用できるので、それを使っていきます。
まずは、畳み込みニューラルネットワークやコンペティションのことは一旦忘れて、単純に ImageDataGenerator を使って画像を生成してみます。データの下準備は、前回までとほぼ同じです。
from keras.models import Sequential from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten from keras.utils import to_categorical from keras.preprocessing.image import ImageDataGenerator import matplotlib.pyplot as plt import seaborn as sns import numpy as np
train = np.loadtxt('/root/practice/digit/csv/train.csv', skiprows=1, delimiter=',') x_test = np.loadtxt('/root/practice/digit/csv/test.csv', skiprows=1, delimiter=',') # print(train.shape) # print(x_test.shape) # 1列目と2〜785列目を分ける y_train, x_train = np.split(train, [1], 1) # print(x_train.shape) # print(y_train.shape) # 形状を枚数 × 28 × 28 × 1 に変形する x_train = x_train.reshape(42000, 28, 28, 1) x_test = x_test.reshape(28000, 28, 28, 1) # print(x_train.shape) # print(x_test.shape) # 1枚分を取り出し表示させてみる plt.imshow(x_train[3]) # ラベル確認 # print(y_train[3])
ここから ImageDataGenerator を使います。 今回はこの手書き数字「4」の画像を元画像として、これをコピーして3枚にし、これを使っていきます。
sample_images = np.array([x_train[3].copy(), x_train[3].copy(), x_train[3].copy()]) # -90 〜 90の範囲でランダムに回転 datagen = ImageDataGenerator(rotation_range=90) # 3枚の画像を生成するので batch_size = 3 戻り値はイテレータ g = datagen.flow(sample_images, batch_size=3) batches = g.next() #(枚数, 縦サイズ, 横サイズ, チャンネル数) --> (3, 28, 28, 1) になる # print(batches.shape) # 画像表示 plt.subplot(1, 3, 1) plt.imshow(batches[0]) plt.subplot(1, 3, 2) plt.imshow(batches[1]) plt.subplot(1, 3, 3) plt.imshow(batches[2])
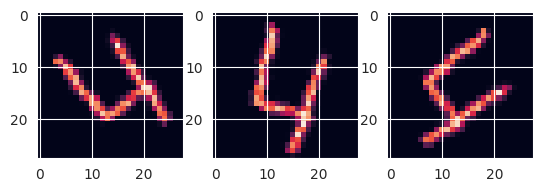
これで実際に画像を表示させてみると、「4」が回転している画像が3枚できたことがわかります。
学習
では、この ImageDataGenerator で、様々な画像データを生成して、学習していきます。CSVからデータを読み込み、訓練データと教師データを分ける処理などは上記と同じで、データの下準備と、ニューラルネットワークの構築部分は前回と同じです。
# 0 - 1 の間の数値にする x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 # one-hot 表現にする y_train = to_categorical(y_train, 10) # モデルは前回の設定と同じ model = Sequential() model.add(Conv2D(filters=32, kernel_size=(4, 4), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Conv2D(filters=64, kernel_size=(4, 4), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(64, activation='relu')) model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.summary()
それでは、ここから画像データを拡張していきます。
epochs = 30 batch_size = 86 datagen = ImageDataGenerator( rotation_range=10, # ランダムに10度回転する zoom_range=0.1, # ランダムに10%ズームする width_shift_range=0.1, # ランダムに横方向に10%ずらす height_shift_range=0.1 # ランダムに縦方向に10%ずらす ) # 第一引数は画像データ、第二引数はラベル generator = datagen.flow(x_train, y_train, batch_size=batch_size)
# 第一引数はデータを生成する generator、引数 steps_per_epoch は1エポック当たり generator を呼び出す回数 history = model.fit_generator( generator, epochs=epochs, steps_per_epoch=(x_train.shape[0] // batch_size), )
generator が生成するデータで学習をするときは、fit_generator メソッドを利用します。引数 steps_per_epoch は画像データ数をバッチサイズで割ったものを指定しています。これで1エポック当たりで、元々の画像データ数と同じ数のデータが生成されます。
学習が終わったら、誤差と精度を求めます。
loss, accuracy = model.evaluate(x_train, y_train) print(loss) print(accuracy)
前回(一つ前のブログ記事の (1) + (4) + (5) + (6))の結果と比較します。
| loss | accuracy | |
|---|---|---|
| 前回 | 0.008217111229896545 | 0.9972618818283081 |
| 今回 | 0.011472832411527634 | 0.9966190457344055 |
前回と比較して誤差・精度共に良い結果になりませんでした。
この学習後のニューラルネットワークで予測を行い、その結果を kaggle に提出してみます。
predicts = model.predict(x_test) # 最も値の大きいものが予測された値なので、それを取り出す predicts_label = np.argmax(predicts, axis=1) # CSVを出力するためのデータを生成 df = pd.DataFrame({ 'imageId': list(range(1, len(predicts)+ 1)), 'Label': predicts_label }) # CSV出力 df.to_csv("/root/practice/digit/csv/predictions.csv", index=False)
すると、なんとスコアが更新されました!!!!!!!!!

訓練データに対しては前回の結果を上回ることはできませんでしたが、テストデータに対しては良い結果を得ることができたようです。